*Originally published in [The AI Monitor](https://theaimonitor.substack.com/p/ai-in-software-development) · 2024-10-08*
[Read on Substack →](https://theaimonitor.substack.com/p/ai-in-software-development)
---
[](https://substackcdn.com/image/fetch/$s_!dAXk!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F23d619f5-2360-4348-b3d8-1c8d8705a59b_1188x696.png)
We built machines to write our code. Now we face the question of whether we can trust what they produce.
Every line an AI generates is a line a developer did not scrutinize. Every function autocompleted is a function accepted on faith. We have traded the friction of writing for the illusion of speed. We have outsourced authorship and kept the signature. We may have given up the vigilance that comes from actually making things.
The rise of AI-assisted programming represents something more than a productivity gain. It represents a fundamental shift in the relationship between developers and the software they ship. When a human writes code, that human understands, at least in principle, what the logic does. When a machine writes it, we have introduced a black box into our most critical infrastructure. The question is not whether these systems can generate functional programs. It is whether we will treat that output with the suspicion it deserves.
## How AI Learns to Code
Large language models learn to program the way they learn everything else: by absorbing patterns from vast training datasets. These systems process billions of lines of publicly available code, learning not just syntax and structure but also the habits, shortcuts, and mistakes of the programmers who wrote that material. This is both their power and their weakness.
[](https://substackcdn.com/image/fetch/$s_!WoPW!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Ff957d726-9b6e-4dbd-a0d3-6e1efb327588_969x639.png)
During training, a model optimizes its parameters to predict what comes next in a sequence. Show it the beginning of a function, and it learns to complete it. Show it enough functions, and it learns what they look like across thousands of different contexts. The result is a system that can produce syntactically correct, often functional programs with remarkable speed.
But here is what we forget: the model absorbs whatever exists in the training corpus. Good patterns. Bad patterns. All of them. If the source material contains insecure practices, the model learns insecure practices. Hardcoded credentials, deprecated cryptographic algorithms, patterns that invite SQL injection. Contaminated soil grows poisoned crops. The system cannot distinguish good practice from bad. It only knows what it has seen.
[](https://substackcdn.com/image/fetch/$s_!OACB!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F5d6c114f-fde9-416e-b4c5-79ef1a35734b_761x640.png)
The foundational research by Carlini and colleagues demonstrated that GPT-2 could reproduce verbatim training sequences, including email addresses, phone numbers, and snippets that were never meant to leave their original context. Subsequent research has confirmed this phenomenon extends to larger models. When a language model trains on a trillion tokens, it does not just learn patterns. It remembers specifics. This is model memorization, and it poses risks that most organizations have not begun to address.
These mechanics explain how flaws enter generated output. But mechanism is only half the picture. Frequency matters just as much.
## The Evidence We Cannot Ignore
These safety concerns are real, not abstract. Researchers measured them.
A peer-reviewed study analyzing snippets produced by GitHub Copilot found that more than one-third contained security gaps, regardless of the programming language used. The 2021 Pearce study: 36.54% vulnerable. The 2023 replication: 27%. The defects were not exotic edge cases. They were the common failures that security professionals have fought for decades: hardcoded credentials, inadequate input validation, patterns that invite injection attacks. The automated assistants did not invent new ways to fail. They simply propagated the old ones at machine speed.
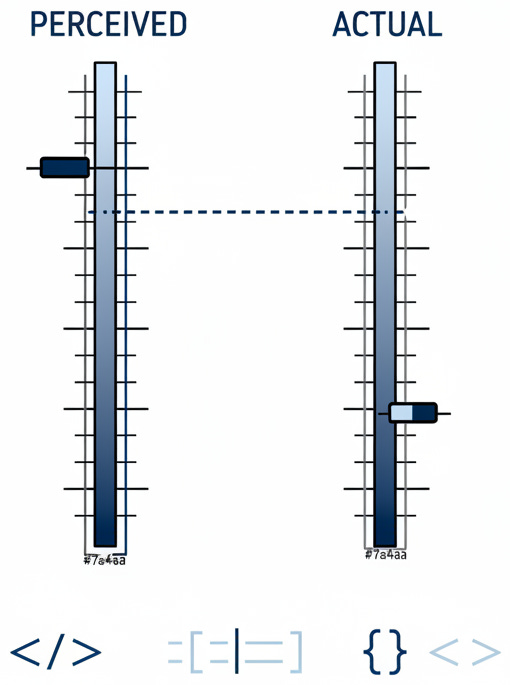
A Stanford study found something equally troubling. Programmers using these tools wrote less secure software but were more likely to believe they had written safe code. The assistant created confidence without competence. This is perhaps the deeper risk: not just that AI-written output produces vulnerable applications, but that it does so while making engineers feel they have done their job well.
[](https://substackcdn.com/image/fetch/$s_!YoeR!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fcd9c93d4-069a-40e3-bf13-cefd9d6fd5ee_510x685.png)
Samsung semiconductor engineers uploaded proprietary code to ChatGPT for debugging help. Three separate leaks occurred within twenty days. Samsung banned the tools. By then, it was too late. Sensitive intellectual property had already entered training datasets beyond their control. What the model learns, it may eventually reproduce for anyone who asks the right questions.
These are not isolated failures. They reveal a pattern: how AI tools handle sensitive data explains why breaches keep happening.
## The Mechanics of Risk
Understanding why AI-written programs pose safety challenges requires understanding how these systems actually work.
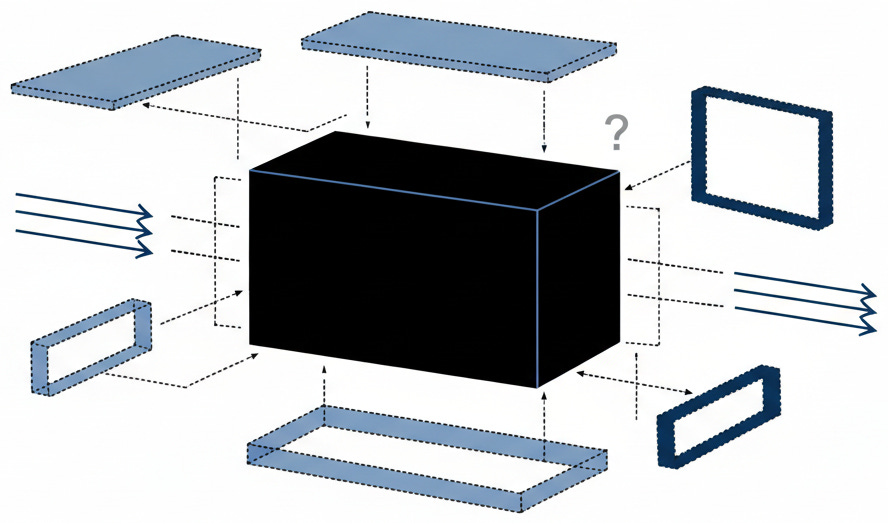
Training data contamination comes first. Language models trained on publicly available repositories inherit whatever defects exist in that material. If a common library contains a weakness that appears in thousands of projects, the model learns that flaw as if it were correct practice. Vulnerable implementations become seeds that sprout across every codebase. One bad pattern. Propagated endlessly.
These systems lack contextual awareness. An LLM can produce syntactically correct output that handles user input, but it has no inherent understanding that such input is adversarial terrain. It does not know that the function it just created will face SQL injection attempts, cross-site scripting attacks, or malicious payloads. It outputs what looks right based on patterns, not what is safe based on threat models.
The black-box nature of these systems compounds the problem. Unlike traditional applications, where every line can be traced to a specific decision, automated output emerges from layers of mathematical transformations. You cannot ask the tool why it chose a particular implementation. You cannot review its reasoning. You can only examine what it produced and hope you catch what it got wrong.
[](https://substackcdn.com/image/fetch/$s_!pckT!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F95bc958f-16a7-4f4d-ae71-421984a11ea1_888x523.png)
Finally, there is the memorization problem. Sensitive information in training data can be extracted through carefully crafted prompts. This matters. Proprietary algorithms may resurface. So may API keys. So may credentials that were accidentally exposed in public repositories. The model does not understand secrecy. It only understands that certain tokens tend to follow certain other tokens.
The risks are structural, embedded in how these tools learn and operate. The response must be equally systematic.
## What Vigilance Looks Like
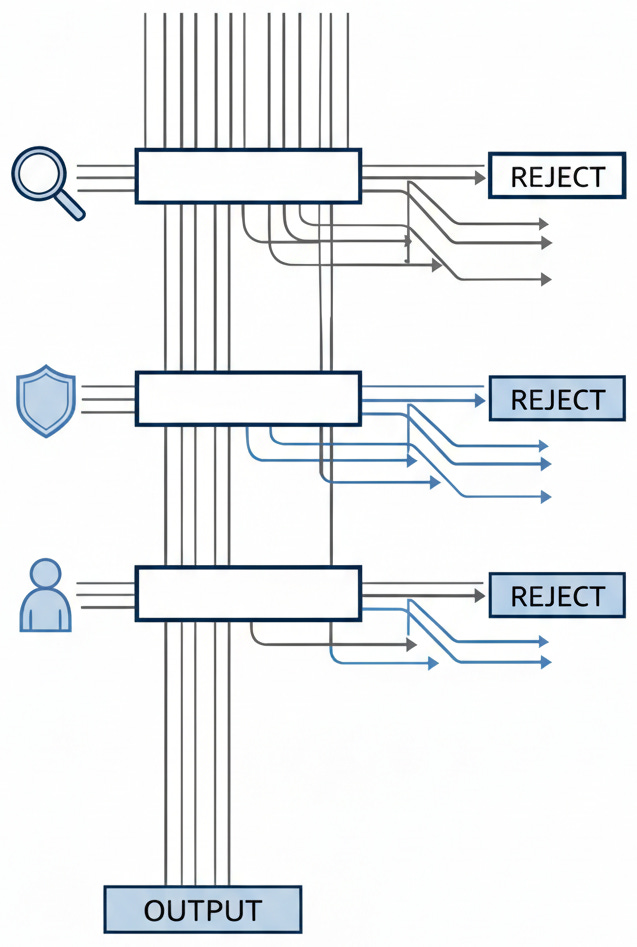
The response to these risks is not to abandon automated programming tools. They offer productivity benefits, and the competitive pressure to adopt them is real. The response is to treat AI-written output the way we should have been treating all external contributions all along: with systematic skepticism.
DevSecOps offers the model. Build protection into every phase. Do not bolt it on at the end. For automated output, this means static analysis tools scanning results in real time. Catch weaknesses before they reach production. Dynamic analysis follows, observing how the software actually behaves when executed in sandboxed environments. Then come manual reviews. These require humans who understand threat models, humans who can identify the context-specific gaps that automated scanners miss.
Input validation deserves particular attention.
A pattern emerges. AI tools skip the safety checks that seasoned coders add by habit. The machines complete patterns. They do not think about defense.
Every function that takes user input needs a hard look. Does it clean the data? Every database query needs the same. Could an attacker slip code through? These are basic questions. Automated output often fails them.
Output encoding matters equally. Cross-site scripting exposures emerge when programs fail to encode data properly before rendering it. Automated scanners catch these gaps most reliably, but only if teams actually run them.
Dependency scanning belongs in this workflow too. When generated code pulls in external libraries, those libraries must be vetted for known defects. Tools like Snyk and OWASP Dependency-Check exist for this. Use them. The code was written by a system that does not understand supply chain risk.
The rule is simple. Verify everything. Treat AI-written code as untrusted until you prove it safe. It should receive the same scrutiny you would apply to contributions from an unknown programmer, because that is essentially what it is.
[](https://substackcdn.com/image/fetch/$s_!qobT!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F70ae1f4b-a7c2-47b2-ab64-0bb569bd991a_637x947.png)
These technical mitigations are well understood. The harder challenge is organizational. How do you build verification into workflows that are optimized for speed?
## The Organizational Challenge
The Venafi Machine Identity Security survey (September 2024) of security leaders reveals a striking tension. More than ninety percent express concern about AI-written software. Yet more than eighty percent report their organizations already use automated tools to create applications. The gap between worry and action is remarkable. Competitive pressure is winning over caution. Organizations feel they cannot afford to fall behind, even if moving forward means accepting risks they cannot fully measure.
This creates a specific failure mode. Engineers adopt automated programming tools because they boost productivity. The applications ship faster. The safety team discovers weaknesses months later, if they discover them at all. By then, the flawed software is in production, the patterns are established, and the real cost of speed becomes visible only in incident reports. We are building on credit.
[](https://substackcdn.com/image/fetch/$s_!QK-T!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F5cf44ebd-9b27-4ff0-a259-cf613c75bdc0_695x1006.png)
The alternative is building protection into the workflow from the start. Make static analysis automatic. Make reviews mandatory for generated sections. Make threat modeling a standard practice, not an occasional exercise. These measures add friction. But friction catches mistakes.
These individual choices compound over time. That is why trajectory matters.
## The Trajectory Before Us
The forces pushing toward greater machine involvement in development are not going to reverse. The tools will improve. The models will grow more capable. The pressure to adopt them will intensify as competitors demonstrate productivity gains. This is the trajectory, and understanding it matters more than predicting specific outcomes.
What would have to change for this trajectory to produce safe applications rather than vulnerable ones? The models themselves would need to be trained on curated datasets with flawed patterns removed. Organizations would need to treat generated output as untrusted by default, with verification built into every workflow. Programmers would need to maintain their understanding of the software they ship, even when they did not write it.
None of these changes is technically impossible. All of them require deliberate effort against the path of least resistance. The current is strong. Swimming against it takes sustained intention.
[](https://substackcdn.com/image/fetch/$s_!V2_d!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F72529bb2-fa81-40df-a5fa-f3735f3cc8ad_1084x387.png)
## The Question We Face
We are in a moment of choice, though it may not feel that way. The tools are here. The adoption is happening. The question is not whether to use machine learning in development. It is whether we will use it thoughtfully or carelessly.
The enthusiasts see efficiency, acceleration, the democratization of programming. The skeptics see opacity, risk we cannot measure until it manifests as incident. Both are seeing accurately. The same tool that writes programs faster also writes weaknesses faster. The same model that completes functions also propagates the mistakes embedded in its training.
Our tools have grown faster than our caution. The code we did not write is still code we ship. The responsibility remains ours.
Here is your Monday morning action: before your next sprint, require that every AI-generated function pass through a static analysis tool before it reaches code review. One gate. One habit. Start there.
* * *
### Further Reading, Background and Resources
**Sources & Citations**
[Extracting Training Data from Large Language Models](https://arxiv.org/abs/2012.07805) \- Carlini et al., USENIX Security 2021. The paper that made “memorization” a household word in AI security circles. Carlini’s team extracted verbatim training sequences from GPT-2: phone numbers, email addresses, code snippets that were never meant to leave their original context. Crucially, extraction attacks scale with model size, meaning every parameter increase that makes AI coding assistants more capable also makes them more likely to regurgitate sensitive data.
[Do Users Write More Insecure Code with AI Assistants?](https://arxiv.org/abs/2211.03622) \- Stanford study, November 2022. This paper captures the most insidious risk the essay describes: AI assistants do not just generate vulnerabilities, they generate confidence. Participants using AI wrote demonstrably less secure code while believing they had written more secure code. The gap between perceived and actual security is where breaches incubate.
[Organizations Struggle to Secure AI-Generated and Open Source Code](https://venafi.com/news-center/press-release/83-of-organizations-use-ai-to-generate-code-despite-mounting-security-concerns/) \- Venafi Survey, September 17, 2024. Yes, Venafi is a security vendor with products to sell. Read it anyway. The value lies in the specific numbers: 92% of security leaders express concern, 83% report their organizations are already using AI for code generation, and 63% have considered banning it. Everyone knows there is a problem; almost no one is stopping.
**For Context**
[Samsung Bans ChatGPT and Other Chatbots for Employees After Sensitive Code Leak](https://www.forbes.com/sites/siladityaray/2023/05/02/samsung-bans-chatgpt-and-other-chatbots-for-employees-after-sensitive-code-leak) \- Forbes, May 2, 2023. Three separate leaks in twenty days from engineers who simply wanted debugging help. Forbes reporting on corporate AI incidents carries weight precisely because exaggeration creates legal exposure.
[Assessing the Security of GitHub Copilot Generated Code](https://arxiv.org/abs/2311.11177) \- arXiv, November 2023. A replication study that found Copilot’s vulnerability rate had improved from 36.54% to 27.25%. Both numbers are alarming, but the trend matters: tools are getting better.
**Practical Tools**
_Static Analysis Integration:_ Integrate tools like [Semgrep](https://semgrep.dev/), [CodeQL](https://codeql.github.com/), or [SonarQube](https://www.sonarsource.com/products/sonarqube/) into your CI/CD pipeline to scan AI-generated code before it reaches production. Configure rules specifically targeting vulnerability patterns most common in LLM outputs: hardcoded credentials, SQL injection vectors, missing input validation.
_Dependency Scanning:_ Use [Snyk](https://snyk.io/) or [OWASP Dependency-Check](https://owasp.org/www-project-dependency-check/) to vet any libraries that AI-generated code pulls in. Automate alerts for known CVEs in dependencies suggested by coding assistants.
_Review Workflow Modifications:_ Require explicit labeling of AI-assisted PRs (add a checkbox to your PR template: “This PR contains AI-generated code”). Route labeled PRs to reviewers with security expertise. Mandate threat modeling for AI-generated code that touches: (1) authentication or session handling, (2) user input processing, (3) database queries, or (4) file system access. Minimum standard: no AI-generated code handling sensitive operations ships without a second reviewer who did not write the original prompt.
**Counter-Arguments**
_The tools will improve faster than the essay acknowledges._ The replication study showing Copilot’s vulnerability rate dropping from 36.54% to 27.25% demonstrates meaningful improvement in under two years. AI coding assistants are early in their development curve. The flaws documented today reflect training on historical code; future models trained on curated, security-reviewed datasets will generate substantially safer outputs. Organizations that build excessive friction into their workflows today may find themselves outcompeted by rivals who adopted AI tools early and iterated their security practices alongside the technology. The essay treats current vulnerability rates as fixed features rather than temporary waypoints on a steep improvement curve.
_Human developers write insecure code too, and at rates that do not look dramatically better._ OWASP’s recurring surveys have documented for two decades that injection flaws, broken authentication, and security misconfigurations persist across human-written software. The essay positions AI-generated code as uniquely dangerous, but the baseline it competes against is not secure code written by infallible humans; it is the same flawed software that has produced the breach landscape we already inhabit. If AI tools generate vulnerabilities at rates comparable to junior developers while producing code ten times faster, the net security posture might improve simply because organizations can afford to invest saved engineering hours into security review.
_Security review should catch vulnerabilities regardless of their source._ The essay’s recommendations, static analysis, dynamic testing, manual review, and dependency scanning, are precisely the practices mature organizations already apply to all code. If your security workflow depends on trusting the source of code rather than verifying its safety, your security workflow was already broken. AI-generated code does not require new defensive techniques; it simply makes existing ones non-optional. Organizations with robust DevSecOps practices should be largely indifferent to whether code originated from a human, an AI, or a copy-pasted Stack Overflow answer.
_Productivity gains enable security investments that would otherwise be impossible._ The essay frames the tradeoff as speed versus safety, but this framing ignores resource allocation. Engineering time is finite. If AI tools reduce the time required to produce functional code by 40%, that capacity can be redirected toward security review, testing, and architectural improvements. Organizations are not choosing between fast-and-vulnerable and slow-and-secure; they are choosing between different allocations of fixed engineering capacity. The same competitive pressure that drives AI adoption also drives companies to avoid the reputational and financial costs of breaches.